ELF Internals
What I wish I knew when learning about ELF (Executable and Linkable Format) files.

Throughout school I worked with ELFs, but I never really dove into their internals. When I did, it was a bit like diving into Jell-o. It was hard for me to visualize and I didn't fully understand the structure.
Here, I try to make ELF files a little easier to visualize. If you're stuck in the Jell-o too, maybe this will help clear a path.
What is an ELF file?
ELF stands for Linkable and Executable Format. Linux users might recognize ELFs as a file they can execute. If you run the file command on an executable, you can verify it's an ELF:
ELF 64-bit LSB shared objectStructure
There are two different types of structures for an ELF binary; one at compile/linking time and one at runtime. This means, if you were to look at an object file (*.o) and an actual executable, the structure would be different. Because the gcc command links and creates the executable automatically for us, we will focus more on the runtime binary. It's just good to know the difference, and that it exists.
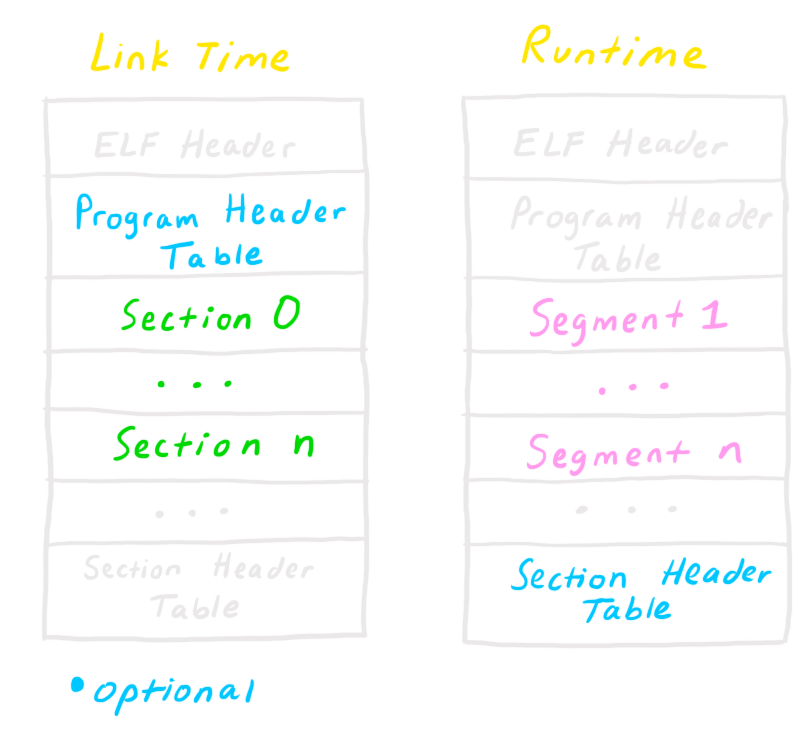
Link Time VS Runtime
Right off the bat you probably have a few questions (I know I did), but don't worry we will cover every part of this image in detail.
Let's break it down and think of the ELF binary like a bird house / hotel.

First, at the top, we have the ELF Header. This tells us all about the file we are looking at. You can read the header from the command line with readelf -h. You'll get output similar to this:
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: DYN (Shared object file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x530
Start of program headers: 64 (bytes into file)
Start of section headers: 6440 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 56 (bytes)
Number of program headers: 9
Size of section headers: 64 (bytes)
Number of section headers: 29
Section header string table index: 28Think of this as the entrance to the bird hotel. There's a large sign that says "Hotel Legolas" and right at the doors has their rates and information about the hotel.
Next, when the bird walks into the hotel, they are greeted by a receptionist at the front desk. The receptionist is lovely and tells them everything about the hotel! Turns out this hotel separates its guests by type of bird on each floor. This means birds that flew in from the tropics stay on floor one, and birds that flew in from the arctic (via plane) stay on floor two, and so on.

Each bird still gets its own room, but they are strategically placed on a specific floor. This makes it easy so when they feed everyone they can do it floor by floor knowing the type of food each floor will want. If a penguin was on the same floor as a parrot, deliveries would be much more complex!

This describes sections and segments.
A section is a bird's room. Each bird occupies their own space in their room. Code or data occupies each section.
Each floor of the hotel is a segment. Segments group sections by similar traits and are composed of these sections.
Continuing with our bird hotel example, all penguins from the arctic will be on floor two. Similarly, all executable sections will be in segment two (only in this example, this is not always the case).
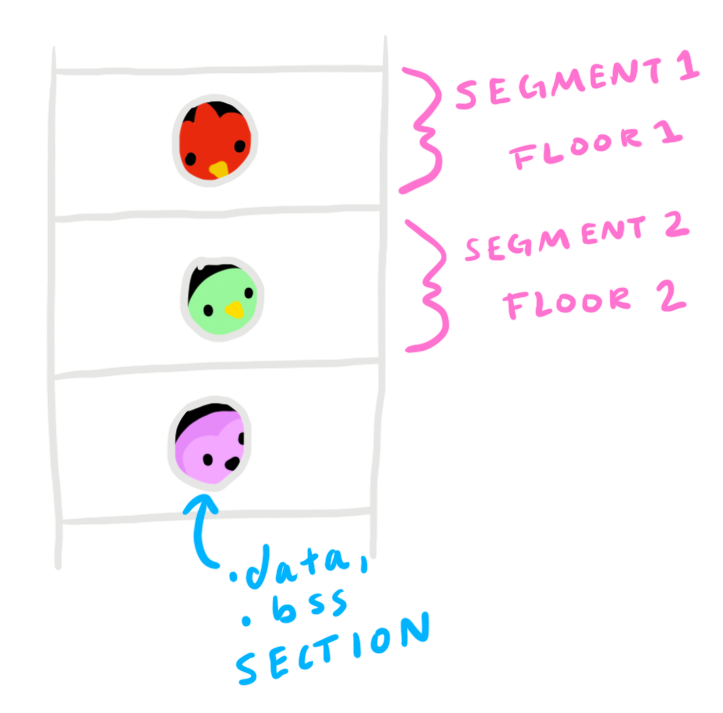
Segments are used at runtime for optimization. Imagine if our wonderful receptionist had to go bring some shrimp to our penguin Tux, but had no clue what floor Tux was on... He'd frantically run around, searching every single floor to deliver the food until he found Tux.
This is where the Program Header Table comes into play. You can see what type of sections (executable, data, etc.) are in segments, just like the receptionist can see what floor the different types of birds are on.
In a sense, this is also why Program Header Tables are only required at runtime, not linking time. It makes the program faster knowing information about each segment.
You can see every segment and Program Header within an ELF binary with the command readelf -l. Here's a snippet of that output:
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .note.ABI-tag .note.gnu.build-id .gnu.hash .dynsym .dynstr
.gnu.version .gnu.version_r .rela.dyn .rela.plt .init .plt .plt.got .text
.fini .rodata .eh_frame_hdr .eh_frame
03 .init_array .fini_array .dynamic .got .data .bss
04 .dynamic
05 .note.ABI-tag .note.gnu.build-id
06 .eh_frame_hdr
07
08 .init_array .fini_array .dynamic .gotNotice there are 8 segments. In each segment there can be many different sections.
You can similarly see every section within an ELF binary with the command readelf -S.
There are 29 section headers, starting at offset 0x1928:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .interp PROGBITS 0000000000000238 00000238
000000000000001c 0000000000000000 A 0 0 1
[ 2] .note.ABI-tag NOTE 0000000000000254 00000254
0000000000000020 0000000000000000 A 0 0 4
[ 3] .note.gnu.build-i NOTE 0000000000000274 00000274
0000000000000024 0000000000000000 A 0 0 4Output is cut for brevity. Notice at the top there are a total of 29 sections.
Sections and segments both have headers in the form of a structure. I won't cover every single member in the structure because it's pretty large and you can find out more about the structures by reading the ELF man page with man elf.
Just know that each header has information such as name, offset, size, address, etc. Section header information is prefixed with sh_ and segment header information is prefixed with p_.
So if I wanted the name of a particular section, I would refer to the sh_name member. For a segment, you guessed it, I would refer to p_name.
Symbols
Another really important thing to know about is symbols. A symbol is just a symbolic reference to some code or data such as a variable or function. When you type out int main, you just created a symbol called main. This symbol resides in the symbol table.
There are two symbol tables: .dynsym and .symtab. .dynsym is the
dynamic symbol table that contains global symbols from some external source. This is where you would find functions such as printf provided when you type #include <stdio.h>.
The other symbol table, .symtab contains all of the symbols local to your binary and the symbols inside of .dynsym.
You can see all symbols with the command readelf -s (and probably want to pipe into less because of how many symbols there are).
As mentioned before, int main creates a symbol called main. We can see this in a
sample binary as follows:
$ readelf -s main | grep "main"
3: 0000000000000000 0 FUNC GLOBAL DEFAULT UND
__libc_start_main@GLIBC_2.2.5 (2)
34: 0000000000000000 0 FILE LOCAL DEFAULT ABS main.c
49: 0000000000000000 0 FUNC GLOBAL DEFAULT UND
__libc_start_main@@GLIBC_
58: 000000000000063a 23 FUNC GLOBAL DEFAULT 14 mainThe last line shows us that our function main is at address 0x63a. We can double check this with GDB by putting a breakpoint at main.
gdb➤ b main
Breakpoint 1 at 0x63e: file main.c, line 5.GDB put the breakpoint at the address we expected, which is great! That means that when we want to know the location of some variable, we can look to the symbol table.